



Deducción de las fórmulas para la incertidumbre
De Laplace
Error estadístico
En otros artículos se enuncian las expresiones para, dado un conjunto de medidas xi de una misma magnitud x, establecer qué valor le asignamos a la medida y a su error como
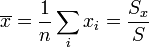
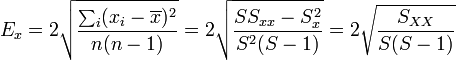
con 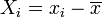 la variable relativa a la media.
la variable relativa a la media.
La justificación de estas fórmulas proviene de una hipótesis básica: que existe una cierta distribución para las distintas medidas.
Supongamos que hiciéramos muchas medidas de esta magnitud y fuéramos clasificando los resultados según la frecuencia con que aparece cada valor. Cuando el número de medidas tiende a infinito obtenemos lo que se llama la función de distribución, p(x).
Esta función nos permite obtener la probabilidad de un resultado concreto, de un intervalo de valores, o la probabilidad para una variable A, función de x.
Dada la función de distribución de la variable x, p(x), el valor esperado (para entendernos, el promedio) de la variable A(x) viene dado por
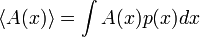
que, en palabras, significa que el promedio de A no es más que la suma de todos los valores, teniendo en cuenta que algunos valores de x aparecen más a menudo que otros.
Las funciones de distribución, p(x), pueden ser de diferentes tipos, pero la más común es la llamada distribución gaussiana, con forma de campana, como la curva continua de la figura anterior.
Dada la función de distribución de una magnitud, dos son sus características principales:
- Media
- o esperanza. Equivale a la media aritmética de los resultados, cuando el número de medidas tiende a infinito. Para una distribución gaussiana, la media corresponde al valor de x para el máximo de la campana. Representaremos la media de la distribución como
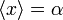
- Varianza
- Se define como
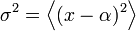
- y da una medida de la dispersión de los datos alrededor del valor medio, esto es, de la anchura de la distribución.
- Para ser más precisos, la raíz de la varianza se denomina la desviación cuadrática media, σ, y, para una distribución gaussiana, es igual a la mitad de la anchura de la campana, medida a una altura e − 1 / 2 = 0.61$ del máximo.
Para el caso de una distribución gaussiana, si tomamos una banda de anchura 2σ alrededor de la media, la probabilidad de que nuestras medidas queden dentro de este intervalo es de un 95.5%. Se entiende entonces que, adoptando el criterio del 95% para la banda de error, una muy buena aproximación para el error de una cierta cantidad es
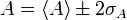
Como criterio supondremos que, dado un conjunto de datos, que suponemos que sigue una cierta distribución de probabilidad, el valor “real” de la medida es la media de la distribución correspondiente.
El problema que surge es que la media de la distribución (y la desviación cuadrática media) sólo se conoce tras infinitas medidas, lo cual la hace inalcanzable.
Se trata entonces de, con un número finito de datos, hallar la mejor aproximación posible a la media.
Una forma de obtenerla es mediante el método de mínimos cuadrados. Cuando se consideran infinitas medidas, se verifica que la cantidad
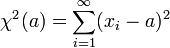
es mínima cuando a = α, esto es, para la media de la distribución. La idea es mantener esta expresión para un número finito de datos. La mejor estimación para la media de la distribución será aquel valor de a que haga mínima la cantidad
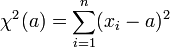
Podemos interpretar este resultado gráficamente. Supongamos que anotamos las diferentes medidas como alturas en una escala. Se trata de hallar un valor que sea la mejor aproximación a todos los datos. Para cada valor tomamos la diferencia entre la medida y este valor. Será una cierta cantidad, que podemos considerar el error de cada dato individual. Elevándola al cuadrado (para que sea siempre positiva) y sumando para todos los datos, el valor mínimo nos dará la mejor aproximación simultánea a todos los datos, aunque puede que no coincida con ninguna de las medidas.
Aplicando la fórmula para el mínimo de una función tenemos
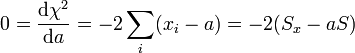
donde hemos separado los dos sumandos y sacado factor común. El valor óptimo será entonces
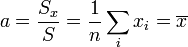
esto es, la media aritmética. Esto está en perfecto acuerdo con la idea de que la media de la distribución coincide con la media aritmética cuando el número de medidas tiende a infinito.
Para hallar el error de esta estimación, partimos de que si tenemos un conjunto de medidas independientes entre sí, se verifica que la varianza de la suma es la suma de las varianzas
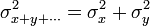
por lo que
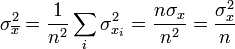
donde 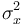 es la varianza de la distribución de los datos, que también debemos estimar.
es la varianza de la distribución de los datos, que también debemos estimar.
Para hallar la aproximación a la varianza, puede hacerse un razonamiento similar al de la media, pero ligeramente más complicado. Sabemos que, en el límite de infinitas medidas, la varianza verifica
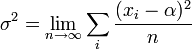
Si intentamos extender esta fórmula a un número finito de datos, debemos tener en cuenta que la propia media aritmética está sometida a error, de forma que la mejor aproximación a la varianza de los datos es
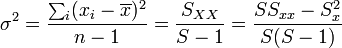
La razón de que aparezca n − 1 en lugar de n en el denominador se debe precisamente a que 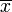 es una aproximación a la verdadera media de la distribución y no coincide exactamente con ella.
es una aproximación a la verdadera media de la distribución y no coincide exactamente con ella.
La estimación de la varianza de la media será entonces
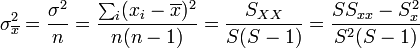
La aproximación a la desviación cuadrática media será la raíz de esta cantidad, por lo que la mejor aproximación a la magnitud y su error será
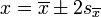
que es la expresión que aparece en el artículo correspondiente.

